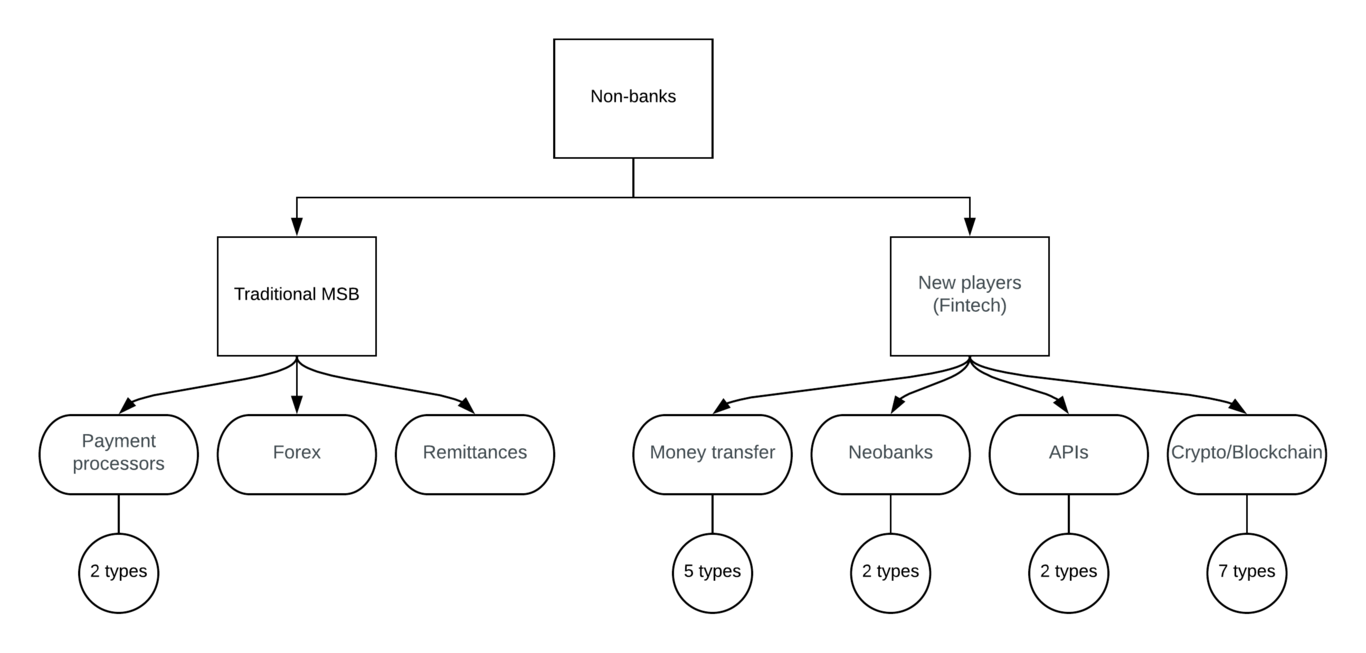
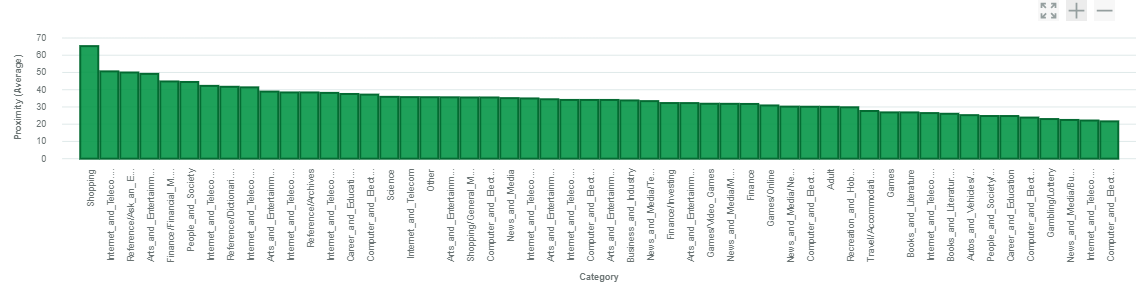
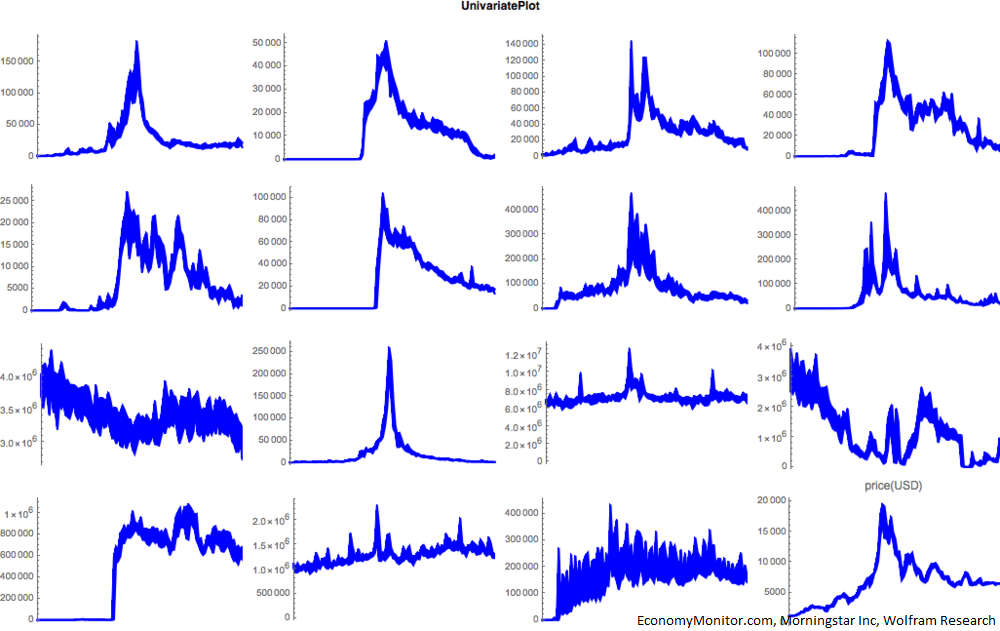
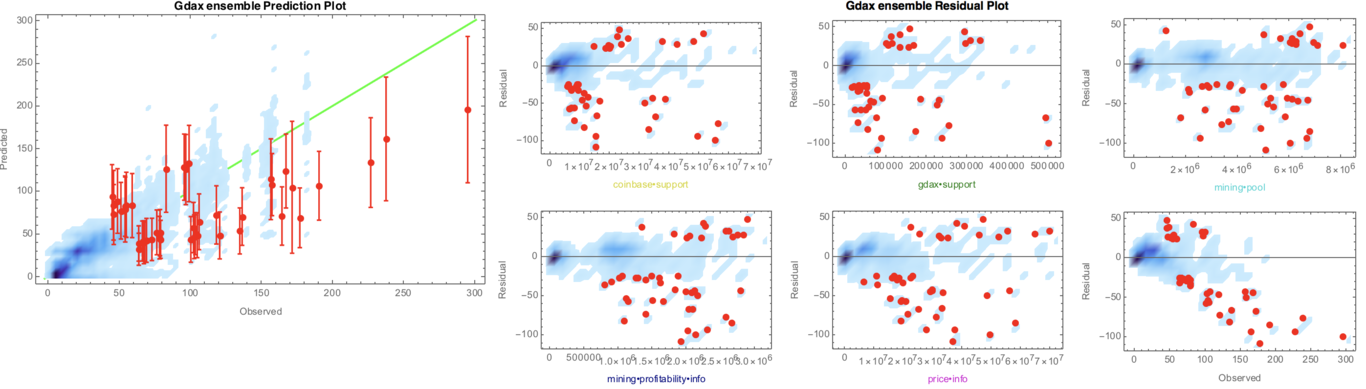
IntroductionOn prepared testimony to the House of Representatives Committee on Financial Services, the Secret Service stated that "Digital currencies have the potential to support more efficient and transparent global commerce and to enhance U.S. economic competitiveness. However, because digital currencies continue to be used to facilitate illicit activity, law enforcement must adapt our investigative tools and techniques \cite{services}". Despite the forensics angle on most investigative tools, applied science can also provide support in the form of early warning systems. Here we describe the algorithmic components for a suite of tools that detect patterns on user behavior, that can inform the authorities where to perform a network intervention. The end product has the form of an education project: a source of information containing those tools and datasets. We seek to evolve AIs that can learn what is important to humans. The optimization objective is to minimize error while keeping complexity manageable: we do not seek to eliminate the error (that will model noise as signal, and introduce overfitting). For practical purposes, there is a level of error we can live with, and there are also limits to human cognition (e.g. how many variables we can think of at the same time, and how many variable relationships). Ultimately, we want AIs that can gain situational awareness in the way humans do. Network inference \cite{Tieri_2019} is the discipline concerned with the dynamic modeling of biologicals networks and has been approached with the use of machine learning \cite{Spirtes_1993} and non-linear modeling techniques (Oates 2012). Using the biological metaphor as inspiration, we use a genetic programming approach. We focus on "inferential sensors" in the points of interest to preserve the integrity of the financial system, the applications include prevention of investment fraud, computer hacking/ransomware scams, identity theft. Inoculation The key idea is that it is easier to cure people in the early stages of infection -influence human behavior, and, prevent machines to learn bad habits. Those users who conduct dark web-related activity in the regular web are still "newbies" (otherwise they would be in the dark web already), and therefore they are more susceptive to an intervention to modify their behavior. Data types The following use cases are based on blockchain and web panel datasets only. At this stage, we use global data and daily time granularity, although detail for specific countries, major US metro areas, and intraday sampling is possible. Those data points can be augmented with government intelligence (e.g. geodata), and/or dark web clickstream datasets, when available. Use cases In the following cases, we symbolically regress TOR browser downloads and cryptocurrencies price action on several real-world time series to find relationships regarding aspects such as deterioration of trust in the traditional financial system \cite{Venegas_2018}, the rise of some types of cyber crimes, among others. The modeling method is genetic programming. As a follow-up step, we investigate causation using several signal processing and AI techniques.