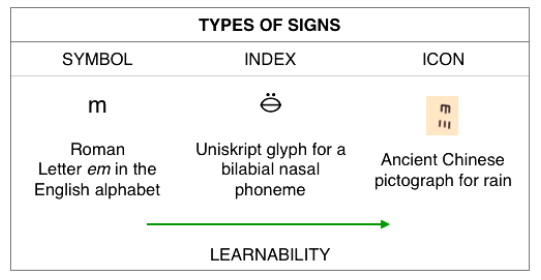
The term uniskript was coined to refer to a class of phonologically engineered alphabets that employ visual-featural indexicality combined with sound-shape congruency to represent speech. In this working paper, I introduce the uniskript methodology, an alphabet generator technique that uses indices instead of symbols to represent the flow of speech. I refer to the Peircean theory of signs to explain the crucial semiotic distinction between uniskript and the traditional alphabets: in uniskript, an icon resembling relevant articulatory features of a given phoneme is used to index sound to shape. I also indicate how the findings in sound-symbolism were incorporated into the indices to facilitate cross-modal correspondences. I propose that uniskript indexical nature and sensorial mappings can explain why it is so much easier to learn than symbolic and sensory incongruent alphabets. I then briefly discuss how the study of uniskript alphabets can shed some light on the role of cross-modal correspondences in learning. It can also bring a deeper understanding of the role of phonology in sound symbolism. Finally, I refer to some applications of uniskript in the teaching of literacy and in remediating reading issues and illustrate the entire concept by introducing a uniskript alphabet developed as a tool to teach pronunciation in an ESL program. keywords: uniskript, alphabets, sound symbolism, sound-shape iconicity, cross-modal congruency, phonology, second language learning, pronunciation in L2